3. Coding with Style
이 장의 내용은
▶ 코드 문서화의 중요성과 사용할 수 있는 주석 스타일 종류
▶ 분해의 의미와 사용 방법
▶ 명명 규칙이란
▶ 서식 규칙이란
코드를 작성하는 키보드 앞에서 매일 몇 시간을 보내려면, 그 모든 작업에 대해 자부심을 가져야 한다. 작업을 완료하는 코드를 작성은 프로그래머 작업의 일부일 뿐이다. 결국 누구나 코딩의 기초를 배울 수 있다. 스타일로 코딩하려면 진정한 마스터가 필요하다.
이 장에서는 "무엇이 좋은 코드를 만드는가?"라는 질문을 탐구한다. 그 과정에서 C++ 스타일에 대한 여러 접근 방식을 보게 될 것이다. 알게 되겠지만, 단순히 코드 스타일을 변경하는 것으로 매우 다르게 보일 수도 있다. 예를 들어, Windows 프로그래머가 작성한 C++ 코드에는 Windows 규칙을 사용한 Windows 스타일을 가지는 경우가 있다. macOS 프로그래머가 작성한 C++ 코드와 거의 완전히 다른 언어처럼 보여진다. 몇 가지 다른 스타일에 노출되면 당신이 알고 있다고 생각했던 C++와 거의 흡사한 C++ 소스 파일을 열 때 얻게 되는 가라앉은 느낌을 피하는 데 도움이 될 것이다.
THE IMPORTANCE OF LOOKING GOOD (좋아 보이는 것의 중요성)
스타일적으로 "good" 코드를 작성하려면 시간이 걸린다. XML 파일을 구문 분석하기 위해 빠르고 간단한 프로그램을 사용하는 데 많은 시간이 필요하지 않을 것이다. 기능적 분해, 적절한 주석과 깨끗한 구조로 동일한 프로그램을 작성하면 더 많은 시간이 소요된다. 그만한 가치가 있을까?
Thinking Ahead (미리 생각하기)
신입 프로그래머가 지금부터 일년 후에 당신의 코드로 작업을 한다면, 당신은 당신의 코드에 대해 얼마나 확신할 수 있겠는가? 점점 더 복잡해지는 웹 애플리케이션 코드에 직면한 내 친구는, 그의 팀에게 일년 후에 시작하게 될 가상의 인턴에 대해 생각해 보라고 격려했다. 문서와 무서운 다중 페이지 기능이 없는 상황에서 이 가여운 인턴이 어떻게 코드 기반에서 속도를 낼 수 있을까? 코드를 작성할 때, 새로운 사람이나 심지어 당신이 미래에 코드를 유지 관리해야 한다고 상상해보라. 어떻게 그것을 작업했는지, 당신은 여전히 기억할 수 있겠는가? 도움을 받을 수 없으면, 당신은 어떻게 할 것인가? 잘 작성된 코드는 읽고 이해하기 쉽기 때문에 이러한 문제를 피할 수 있다.
Elements of Good Style (좋은 스타일의 요소)
"스타일이 좋은" 코드의 특성을 열거하는 것은 어려운 일이다. 시간이 지나면서, 다른 사람들이 작성한 코드에서 좋아하는 스타일을 찾고 유용한 기술을 알게 될 것이다. 아마도 더 중요한 것은, 피해야 할 것을 알려주는 끔직한 코드를 만나는 것이다. 그러나 좋은 코드는 이 장에서 살펴보는 몇 가지 보편적인 신조를 공유한다 :
▶ Documentation (문서)
▶ Decomposition (분해)
▶ Naming (명명)
▶ Use of the language (언어의 사용)
▶ Formatting (서식)
DOCUMENTING YOUR CODE (코드 문서화)
프로그래밍 컨텍스트에서 문서는 일반적으로 소스 파일에 포함된 주석을 나타낸다. 주석은 당신이 함께 제공되는 코드를 작성할 때 머릿속으로 무엇을 하려고 했는지 세상에 말할 수 있는 기회이다. 코드 자체를 보면 명확하지 않은 것은 무엇이든 말할 수 있는 곳이다.
Reasons to Write Comments (주석을 작성하는 이유)
주석을 작성하는 것이 좋은 생각처럼 보일 수 있지만, 코드에 주석을 추가해야 하는 이유에 대해 생각해 본 적이 있는가? 때때로 프로그래머는 주석이 중요한 이유를 완전히 이해하지 못한 채 주석의 중요성을 인정한다. 몇 가지 이유가 있으며, 모두 이 장에서 살펴본다.
Commenting to Explain Usage (사용법을 설명하는 주석 작성)
주석을 사용하는 한 가지 이유는 클라이언트가 코드와 상호 작용하는 방법을 설명하는 것이다. 일반적으로 개발자는 단순히 함수의 이름, 반환 값의 유형, 파라미터의 이름과 유형을 기반으로 함수가 수행하는 작업을 이해할 수 있어야 한다. 그러나 모든 것을 코드로 표현할 수 있는 것은 아니다. 함수 사전, 사후 조건1과 함수에서 발생할 수 있는 예외는 주석으로만 설명할 수 있는 사항이다. 제 생각에는 사전, 사후 조건과 예외와 같은 유용한 정보가 실제로 추가되는 경우에만 주석을 추가하는 것이 좋다. 그렇지 않으면 주석을 생략해도 된다. 그럼에도 불구하고 함수에 사전 또는 사후 조건이 없는 경우는 드물다. 결론부터 말하자면 개발자는 함수에 주석이 필요한지 여부를 결정한다. 숙련된 프로그래머는 이를 결정하는 데 문제가 없지만, 경험이 적은 개발자가 항상 올바른 결정을 내리는 것은 아니다. 그렇기 때문에 일부 회사에는 모듈이나 헤더 파일에서 공개적으로 액세스할 수 있는 각각의 함수나 메서드가 수행하는 작업, 인수가 무엇인지, 반환하는 값과 발생할 수 있는 예외를 설명하는 주석이 있어야 한다는 규칙이 있다.
주석은 코드로 표현할 수 없는 모든 것을 영어(해당 언어)로 표현할 수 있는 기회를 제공한다. 예를 들어, C++ 코드에서는 openDatabase()가 아직 호출되지 않은 경우 데이터베이스 객체의 saveRecord() 메서드가 예외를 발생시킨다는 것을 표시할 방법이 없다. 그러나 주석은 다음과 같이 이 제한 사항을 기록하기에 완벽한 장소가 될 수 있다 :
// Throws :
// DatabaseNotOpenedException if the openDatabase() method has not
// been called yet.
int saveRecord(Record& record);saveRecord() 메소드는 Record 객체에 대한 non-const 레퍼런스를 허용한다. 사용자는 이것이 const에 대한 레퍼런스가 아닌 이유를 궁금해 할 수 있으므로, 주석으로 설명해야 한다 :
// Parameters :
// record: If the given record does not yet have a database ID, then the method
// modifies the record object to store the ID assigned by the database.
// Throws :
// DatabaseNotOpenedException if the openDatabase() method has not
// been called yet.
int saveRecord(Record& record);C++ 언어는 메서드의 반환 유형을 지정하도록 강제하지만, 반환된 값이 실제로 무엇을 나타내는 것인지 말할 수 있는 방법은 제공하지 않는다. 예를 들어, saveRecord() 메서드의 선언은 int(이 섹션에서 더 자세히 논의되는 잘못된 설계 결정)를 반환한다고 나타낼 수 있지만, 해당 선언을 읽는 클라이언트는 int가 무엇을 의미하는지 알지 못한다. 주석은 그 의미를 설명한다 :
// Parameters :
// record: If the given record does not yet have a database ID, then the method
// modifies the record object to store the ID assigned by the database.
// Return: int
// An integer representing the ID of the saved record.
// Throws :
// DatabaseNotOpenedException if the openDatabase() method has not
// been called yet.
int saveRecord(Record& record);이전 주석은 메서드가 하는 일을 설명하는 문장을 포함하여 saveRecord() 메서드에 대한 모든 것을 형식적인 방식으로 문서화한다. 일부 회사는 이러한 형식적이고 철저한 문서화를 요구하지만, 항상 이러한 스타일의 주석 작성을 권장하지는 않는다. 예를 들어, 첫 번재 라인은 함수 이름이 자명하기 때문에 다소 쓸모가 없다. 파라미터에 대한 설명은 예외에 대한 주석과 마찬가지로 중요하므로 반드시 유지해야 한다. 이 버전의 saveRecord()가 일반 int를 반환하기 때문에 반환 유형이 정확하게 무엇을 나타내는지 문서화해야 한다. 그러나 보다 더 좋은 설계는 일반 int 대신 RecordID를 반환하는 것으로, 반환 유형에 대한 주석을 추가할 필요가 없다. RecordID는 단일 int 데이터 멤버가 있는 단순한 클래스 일 수 있지만, 더 많은 정보를 전달하며 필요한 경우 나중에 더 많은 데이터 멤버를 추가할 수 있다. 따라서 다음은 saveRecord() 메서드에 대한 권장 사항이다 :
// Parameters :
// record: If the given record does not yet have a database ID, then the method
// modifies the record object to store the ID assigned by the database.
// Throws :
// DatabaseNotOpenedException if the openDatabase() method has not
// been called yet.
RecordID saveRecord(Record& record);참고
회사의 코딩 가이드 라인이 함수에 대해 공식적으로 주석을 작성하도록 강요하지 않는 경우, 주석을 작성할 때 상식을 사용한다. 함수 이름, 반환 유형, 파라미터의 이름과 유형에 따라 명확하지 않은 내용만 주석에 명시한다.
경우에 따라, 함수의 파라미터와 반환 유형은 일반적이며 모든 종류의 정보를 전달에 사용할 수 있다. 이 경우 전달되는 유형을 정확히 문서화해야 한다. 예를 들어, Windows의 메시지 핸들러는 LPARAM과 WPARAM의 두 파라미터를 허용하고 LRESULT를 반환할 수 있다. 세 가지 모두 원하는 거의 모든 것을 전달하는 데 사용할 수 있지만, 유형은 변경할 수는 없다. 예를 들어 type casting을 사용하여 간단한 정수나 일부 개체에 대한 포인터를 전달하는 데 사용할 수 있다. 문서는 다음과 같을 수 있다 :
// Parameters:
// WPARAM wParam: (WPARAM)(int): An integer representing...
// LPARAM lParam: (LPARAM)(string*): A string pointer representing...
// Returns: (LRESULT)(Record*)
// nullptr in case of an error, otherwise a pointer to a Record object
// representing...
LRESULT handleMessage(WPARAM wParam, LPARAM lParam);공개되는 문서에는 구현이 아니라 코드의 동작을 설명해야 한다. 동작에는 입력, 출력, 오류 조건과 처리, 의도된 사용, 성능 보장이 포함된다. 예를 들어, 단일 난수를 생성하기 위한 호출을 설명하는 공개 문서에는 파라미터를 사용하지 않고 이전에 지정된 범위안의 정수를 반환하고 문제가 발생할 때 발생(throw)될 수 있는 모든 예외를 나열해야 한다. 이 공개 문서에는 실제로 숫자를 생성하는 선형 합동 알고리즘의 세부 사항을 설명하지 않아야 한다. 코드 사용자를 대상으로 하는 주석에 너무 많은 구현 세부 정보를 제공하는 것은 공개 주석을 작성할 때 가장 흔한 실수일 것이다.
Commenting to Explain Complicated Code (복잡한 코드를 설명하기 위한 주석)
좋은 주석은 실제 소스 코드 내에서도 역시 중요하다. 사용자의 입력을 처리하고 결과를 콘솔에 출력하는 간단한 프로그램에서는 모든 코드를 읽고 이해하는 것이 쉬울 것이다. 그러나 전문 분야에서는 검사로 단순히 이해하기에는 알고리즘적으로 복잡하거나 무척 난해한 코드를 종종 작성해야 한다.
다음 코드를 고려한다. 코드는 잘 작성됐지만, 그것이 무엇을 하는지 즉시 드러나지 않을 수 있다. 이전에 본 적이 있다면 알고리즘을 인지할 수 있지만, 초보자는 아마도 코드가 작동하는 방식을 이해하지 못할 것이다.
void sort(int data[], size_t size)
{
for (int i { 1 }; i < size; ++i) {
int element { data[i] };
int j { i };
while (j> 0 && data[j-1]> element) {
data[j] = data[j - 1];
j--;
}
data[j] = element;
}
}더 나은 접근 방식은 사용 중인 알고리즘을 설명하고 불변성을 문서화(루프)하는 주석을 포함하는 것이다. 불변성은 예를 들면 루프 반복과 같은 코드를 실행하는 동안 true이어야 하는 조건이다. 뒤이어 수정된 함수에서는 상단의 주석으로 높은 수준의 알고리즘을 설명하고, 인라인 주석은 혼동될 수 있는 특정 행을 설명한다:
// Implements the "insertion sort" algorithm. The algorithm separates the
// array into two parts--the sorted part and the unsorted part. Each
// element, starting at position 1, is examined. Everything earlier in the
// array is in the sorted part, so the algorithm shifts each element over
// until the correct position is found to insert the current element. When
// the algorithm finishes with the last element, the entire array is sorted.
void sort(int data[], size_t size)
{
// Start at position 1 and examine each element.
for (int i { 1 }; i < size; ++i) {
// Loop invariant:
// All elements in the range 0 to i-1 (inclusive) are sorted.
int element { data[i] };
// j marks the position in the sorted part where element will be inserted.
int j { i };
// As long as the value in the slot before the current slot in the sorted
// array is higher than element, shift values th the right to make room
// for insertion element (hence the name, "insertion sort") in the correct
// position
while (j> 0 && data[j - 1]> element) {
// invariant: element in the range j+1 to i are> element.
data[j] = data[j - 1];
// invariant: element in the range j to i are>element.
j--;
}
// At this point the current position in the sorted array
// is *not* greater than the element, so this is its new position.
data[j] = element;
}
}새 코드는 확실히 더 장황하지만, 정렬 알고리즘에 익숙하지 않은 독자가 주석이 포함된 코드를 이해할 가능성이 훨씬 더 높다.
Commenting to Convey Meta-information (메타 정보 전달을 위한 주석)
주석을 사용하는 가능한 다른 이유는 코드 자체보다 높은 레벨에서 정보를 제공하는 것이다. 이 meta-information(메타 정보)는 동작의 세부 사항을 다루지 않고 코드 생성에 대한 세부 정보를 제공한다. 예를 들어, 조직에서 각 메소드의 원래 작성자를 추적할 수 있다. 메타 정보를 사용하여 외부 문서를 인용하거나 다른 코드를 참조할 수도 있다.
아래 예제는 작성자, 생성 날짜, 언급되는 특정 기능을 포함한 메타 정보의 여러 인스턴스를 보여준다. 또한 코드 라인에 해당하는 버그 번호와 나중에 코드에서 발생할 수 있는 문제점을 다시 확인하라는 알림과 같은 메타 데이터를 표현하는 인라인 주석이 포함된다.
// Author: marcg
// Date: 110412
// Features: PRD version 3, Feature 5.10
RecordID saveRecord(Record& record)
{
if (!m_databaseOpen) { throw DatabaseNotOpenedException { }; }
RecordID id { getDB()->saveRecord(record) };
if (id ==-1) return -1; // Added to address bug #142 - jsmith 110428
record.setid(id);
// TODO: What if setid() throws an exception? - akshayr 110501
return id;
}변경 로그는 각 파일의 시작 부분에 포함될 수도 있다. 다음은 그러한 변경 로그의 가능한 예를 보여준다:
// Date | Change
//-----------+--------------------------------------------------
// 110413 | REQ #005: <marcg> Do not normalize values.
// 110417 | REQ #006: <marcg> use nullptr instead of NULL.WARNING (주의)
이전 예제("TODO" 주석 제외)의 모든 meta-information(메타 정보)는 Chapter 28, "Maximizing Software Engineering Methods(소프트웨어 엔지니어링 메소드 최대화)"에서 설명한 것처럼 소스 코드 컨트롤 솔루션을 사용(또는 사용해야)할 때 권장하지 않는다. 이러한 솔루션은 수정 날짜, 작성자 이름과 적절하게 사용된 경우 변경 요청과 버그 리포트에 대한 참조를 포함하여 각 수정에 해당하는 주석과 함께 변경 기록을 제공한다. 각 변경 요청이나 버그 수정을 개별적으로 주석 설명과 함께 체크인하거나 커밋해야 한다. 이러한 시스템을 사용하면 메타 정보를 수동으로 추적할 필요가 없다.
또 다른 유형의 메타 정보는 저작권 표시이다. 일부 회사는 모든 소스 파일의 시작 부분에 이러한 저작권 표시를 요구한다.
주석으로 넘어가기는 쉽다. 좋은 접근 방식은 그룹에서 가장 유용한 주석 유형을 논의하고 정책을 수립하는 것이다. 예를 들어, 그룹의 한 구성원이 여전히 작업이 필요한 코드를 나타내기 위해 "TODO" 주석을 사용하지만 이 규칙에 대해 아무도 모르는 경우, 주의가 필요한 코드를 간과할 수 있다.
Commenting Styles (주석 스타일)
조직마다 코드의 주석 처리 방식은 다르다. 일부 환경에서는 코드 문서화에 대한 일관된 표준을 제공하기 위해 특정 스타일이 요구된다. 다른 경우에는, 주석의 양과 스타일이 프로그래머에게 달려 있다. 다음 예제에서는 코드 주석에 대한 여러 접근 방식을 보여준다.
Commenting Every Line (모든 라인에 주석 달기)
문서의 부족함을 피하는 한 가지 방법은 모든 라인에 주석을 포함하여 과도한 문서를 작성하는 것이다. 코드의 모든 라인에 주석을 작성하는 것은 작성하는 모든 것이 특별한 이유가 있어야 한다. 사실 이런 거창한 댓글은 거추장스럽고, 귀찮고, 지루하다. 예를 들면, 다음과 같은 쓸모 없는 주석을 고려해 본다:
int result; // Declare an integer to hold the result.
result = doodad.getResult(); // Get the doodad`s result.
if (result % 2 == 0) { // If the result modulo 2 is 0 ...
logError(); // then log an error,
} else { // otherwise ...
logSuccess(); // log success.
} // End if/else.
return result; // Return the result.이 코드의 주석은 쉽게 읽을 수 있는 영어 이야기의 일부로서 각 라인을 표현한다. 독자가 최소한 기본적인 C++ 기술을 가지고 있다고 가정하면, 이것은 완전히 쓸모가 없다. 이러한 주석은 코드에 대한 추가적인 정보를 추가하지 못한다. 특히 다음 라인을 보면:
if (result % 2 ==0) { // If the result modulo 2 is 0 ...주석은 코드의 영어 번역일 뿐이다. 프로그래머가 값이 2인 결과에 modulo 연산자를 사용한 이유는 말하지 않았다. 다음은 더 나은 주석이 될 것이다:
if (result % 2 ==0) { // If the result is even ...대부분의 프로그래머에게 여전히 명확한 동안, 수정된 주석은 코드에 대한 추가적인 정보를 제공한다. 코드에서 결과가 짝수인지 확인해야 하기 때문에 modulo 연산자 2를 사용한다.
더 좋은 점은, 어떤 표현식이 모든 사람에게 바로 명확하지 않을 수 있는 어떤 작업을 수행하는 경우 이름을 잘 선택한 함수로 바꾸는 것이 좋다. 이렇게 하면 코드가 자체 문서화되어, 함수가 사용되는 위치에 주석을 작성할 필요가 없어져 재사용 가능한 코드가 생성된다. 예를 들어 다음과 같이 isEven() 함수를 정의할 수 있다:
bool isEven(int value) { return value % 2 == 0; }그런 다음 주석 없이 다음과 같이 사용한다:
if (isEven(result)) {장황하고 불필요한 경향이 있음에도 불구하고, 코드가 이해하기 어려운 경우에는 무거운 주석이 유용할 수 있다. 다음 코드도 모든 라인에 주석에 작성하지만, 이런 주석은 실제로 도움이 된다:
// Calculate the doodad. The start, end, and offset values come from the
// table on page 96 of the "Doodad API v1.6."
result = doodad.calculate(Start, End, Offset);
// To determine success or failure, we need to bitwise AND the result with
// the processor-specific mask (see "Doodad API v1.6," page 201).
result &= getProcessorMask();
// Set the user field value based on the "Marigold Formula."
// (see "Doodad API v1.6", page 136)
setUserField((result + MarigoldOffset) / MarigoldConstant + MarigoldConstant);이 코드는 컨텍스트에서 제외되지만, 주석은 각 라인이 수행하는 작업에 대한 좋은 아이디어를 제공한다. 주석이 없이는 &와 관련된 계산과 신비한 "Marigold Formula"을 해독하기 어려울 것이다.
참고
코드의 모든 라인에 주석을 작성하는 것은 일반적으로 보장되지 않지만, 코드가 그것을 요구할 정도로 복잡하다면, 코드를 영어로 번역하지 말고 실제로 무슨 일이 일어나고 있는지 설명한다.
Prefix Comments (접두사 주석)
당신의 그룹은 표준 주석으로 모든 소스 파일을 시작하기로 결정할 수 있다. 이것은 프로그램과 특정 파일에 대한 중요한 정보를 문서화할 수 있는 기회이다. 모든 파일의 맨 위에 있을 수 있는 정보의 예는 다음과 같다:
▶ Copyright information (저작권 정보)
▶ A brief description of the file/class (파일/클래스에 대한 간단한 설명)
▶ The last-modified date* (마지막 수정 날짜)
▶ The original author* (원저자)
▶ A change-log (as described earlier)* (변경 로그 (앞서 설명한 대로))
▶ The feature ID addressed by the file* (파일에서 지정된 기능 ID)
▶ Incomplete features** (불완전한 기능)
▶ Known bugs** (알려진 버그)
* 이러한 항목은 일반적으로 소스 코드 제어 솔루션에서 자동으로 처리된다(Chapter 28 참조).
** 이러한 항목은 일반적으로 버그와 기능 추적 시스템에서 처리된다(Chapter 30. "Becoming Adept at Testing").
개발 환경에서 접두사 주석으로 새 파일을 자동으로 시작하는 템플릿을 만들 수 있다. Subversion(SVN)과 같은 일부 소스 제어 시스템은 메타데이터를 입력하여 지원할 수도 있다. 예를 들어 주석에 $Id$ 문자열이 포함된 경우 SVN은 작성자, 파일 이름, 리비전과 날짜를 포함하도록 주석을 자동으로 확장할 수 있다.
다음은 접두사 주석의 예이다:
// $Id: Watermelon.cpp,123 2004/03/10 12:52:33 marcg $
//
// Implements the basic functionality of a watermelon. All units are expressed
// in terms of seeds per cubic centimeter. Watermelon theory is based on the
// white paper "Algorithms for Watermelon Processing."
//
// The following code is (c) copyright 2017, FruitSoft, Inc. ALL RIGHTS RESERVED
Fixed-Format Comments (고정된 형식 주석)
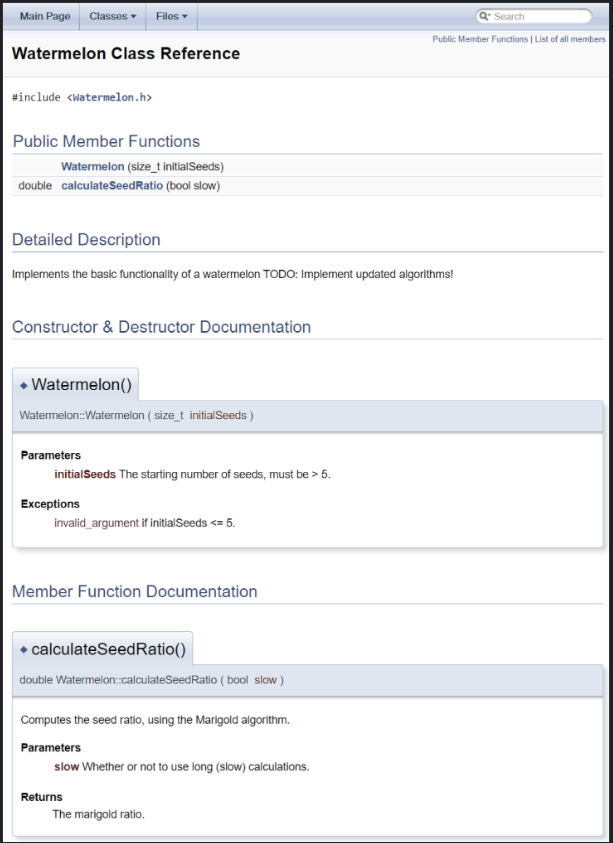
외부 문서 빌더가 구문 분석할 수 있는 표준 형식으로 주석을 작성하는 것은 널리 사용되는 프로그램 방법이다. Java 언어에서 프로그래머는 JavaDoc이라는 도구로 프로젝트에 대한 하이퍼링크 문서를 자동으로 생성하는 표준 형식으로 주석을 작성할 수 있다. C++의 경우, Doxygen(doxygen.org에서 사용 가능)이라는 무료 도구가 주석을 구문 분석하여 HTML 문서, 클래스 다이어그램, UNIX 매뉴얼 페이지와 기타 유용한 문서를 자동으로 작성한다. Doxygen은 C++ 프로그램에서 JavaDoc 스타일 주석도 인식하고 구문 분석한다. 다음 코드는 Doxygen에서 인식하는 JavaDoc 스타일 주석을 보여준다:
/**
* Implements the basic functionality of a watermelon
* TODO: Implement updated algorithms!
*/
export class Watermelon
{
public:
/**
* @param initialSeeds The starting number of seeds, must be> 5.
* @throws invalid_argument if initialSeeds <= 5.
*/
Watermelon(size_t initialSeeds);
/**
* Computes the seed ratio, using the Marigold algorithm.
* @param slow Whether or not to use long (slow) calculations.
* @return The marigold ratio.
*/
double calculateSeedRatio(bool slow);
};Doxygen은 C++ 구문과 @param, @return 및 @throws와 같은 특수 주석 지시문을 인식하여, 사용자 지정 가능한 출력을 생성한다. Figure 3-1은 Doxygen에서 생성된 HTML 클래스 레퍼런스의 예를 보여준다.
문서를 자동으로 생성하는 도구를 사용하는 경우에도, 여전히 쓸모없는 주석을 작성하지 않아야 한다. 이전 코드에서 Watermelon 생성자를 살펴보자. 주석은 설명을 생략하고 파라미터와 파라미터로 발생하는 예외만 설명한다. 다음 예와 같이 설명을 추가하는 것은 불필요하다:
/**
* The Watermelon constructor.
* @param initialSeeds The starting number of seeds, must be> 5.
* @throws invalid_argument if initialSeeds <= 5.
*/
Watermelon(size_t initialSeeds);Figure 3-1에 보여지는 파일과 같이 자동으로 생성된 문서는 개발자에게 클래스와 그들의 관계에 대한 높은 레벨의 설명을 탐색할 수 있도록 하므로 개발 중에 도움이 될 수 있다. 당신의 그룹은 당신이 채택한 주석 스타일로 작업하기 위해 Doxygen과 같은 도구를 쉽게 사용자 정의할 수 있다. 이상적으로는 그룹에서 매일 문서를 작성하는 머신을 설정하는 것이 좋다.
Ad Hoc Comments (임시 주석)
대부분의 경우, 필요에 따라 주석을 사용한다. 다음은 코드 본문에 표시되는 주석에 대한 몇 가지 지침이다:
- 주석을 추가하기 전에, 먼저 코드를 재작업하여 주석을 중복으로 만들 수 있는지 고려한다. 예를 들어 변수, 함수 및 클래스의 이름을 변경, 코드에서 단계를 재정렬, 중간에 잘 명명된 변수를 도입, 등등...
- 누군가 당신의 코드를 읽고 있다고 상상해 본다. 즉각적으로 명확하지 않은 미묘함이 있는 경우, 이를 문서화해야 한다.
- 코드에 이니셜을 넣지 않는다. 소스 코드 제어 솔루션은 이러한 종류의 정보를 자동으로 추적한다.
- 즉각적으로 명확하지 않은 API로 작업을 수행하는 경우, 설명된 해당 API 설명서에 대한 참조를 포함한다.
- 코드를 업데이트할 때, 주석 업데이트를 기억해야 한다. 잘못된 정보로 완전히 문서화된 코드보다 더 혼란스러운 것은 없다.
- 주석을 사용하여 기능을 섹션으로 분리하는 경우, 기능을 여러 개의 더 작은 함수로 분리할 수 있는지 고려한다.
- 공격적이거나 경멸적인 언어를 피한다. 언제 누가 당신의 코드를 보게 될지 알 수 없다.
- 내부 농담을 자유롭게 사용하는 것은 일반적으로 괜찮은 것으로 간주된다. 관리자에게 확인한다.
Self-Documenting Code (자체 문서화 코드)
간혹 잘 작성된 코드는 풍부한 주석이 필요하지 않다. 최고의 코드는 읽을 수 있도록 작성된다. 모든 라인에 주석을 추가하는 경우, 주석에서 말하는 내용과 더 잘 일치하도록 코드를 다시 작성할 수 있는지 고려한다. 예를 들어 함수, 파라미터, 변수, 클래스 등에 설명이 포함된 이름을 사용한다. const를 적절하게 사용한다. 즉 변수가 수정되지 않아야 하는 경우, const로 표시한다. 함수의 단계를 재정렬하여 수행 중인 작업을 더 명확하게 한다. 알고리즘을 더 쉽게 이해할 수 있도록 이름이 잘 지정된 중간 변수를 도입한다. C++는 언어라는 것을 기억한다. 주요 목적은 컴퓨터에게 무엇을 해야 하는지 알려주는 것이지만, 언어의 의미는 읽는 사람에게 그 의미를 설명하는 데 사용될 수도 있다.
자체 문서화 코드를 작성하는 또 다른 방법은 코드를 더 작은 조각으로 나누거나 분해하는 것이다. 분해는 다음 섹션에서 자세히 다룬다.
참고
좋은 코드는 자연스럽게 읽을 수 있으며, 유용한 추가 정보를 제공하기 위한 주석만 필요하다.
DECOMPOSITION (분해)
분해는 코드를 더 작은 조각으로 나누는 관행이다. 코딩 세계에서 소스 코드 파일을 열어 300 라인의 함수와 방대한 중첩된 코드 블록을 찾는 것보다 더 어려운 일은 없다. 이상적으로는 각 함수나 메서드는 단일 작업을 수행해야 한다. 상당히 복잡한 하위 작업은 별도의 함수나 메서드로 분해해야 한다. 예를 들어, 누군가 메서드가 무엇을 하는지 물었을 때 "먼저 A를 수행한 다음 B를 수행한다. 그런 다음 C이면 D를 수행한다. 그렇지 않으면 E를 수행한다.", A, B, C, D와 E에 대해 별도의 도우미 메서드가 있어야 한다.
분해는 정확한 과학이 아니다. 어떤 프로그래머는 어떠한 함수라도 인쇄된 코드가 한 페이지보다 길어서는 안 된다고 말할 것이다. 이것은 경험상 좋은 규칙일 수 있지만, 분해가 절실히 필요한 1/4 페이지의 코드를 찾을 수 있다. 또 다른 경험 규칙은 실제 내용을 읽지 않고 눈을 가늘게 뜨고 코드 형식을 보면 어느 한 영역에서 너무 조밀하게 나타나서는 안 된다는 것이다. 예를 들어, Figure 3-2와 3-3은 콘텐츠에 집중하지 않도록 의도적으로 흐리게 처리한 코드를 보여준다. Figure 3-3의 코드가 Figure 3-2의 코드보다 더 잘 분해되어 있다는 것은 분명하다.


Decomposition Through Refactoring (리팩토링을 통한 분해)
때로는 몇 잔의 커피를 마시면서 실제로 프로그래밍 영역에 있을 때(프로그래밍 작업을 할 때), 코딩을 너무 빠르게 시작하여 원래 해야 하는 일을 정확히 수행하지만 예쁘지 않은 코드로 끝나는 경우가 있다. 모든 프로그래머는 때때로 이렇게 작업을 수행한다. 짧은 기간의 활발한 코딩은 프로젝트 과정에서 때로는 가장 생산적인 시간이다. 코드가 수정되는 시간이 흐르면서 조밀한 코드도 발생한다. 새로운 요구 사항과 버그 수정 사항이 나오면서 기존 코드가 조금식 수정되어 간다. 컴퓨터 용어 cruft는 소량의 코드가 점진적으로 누적되어 한때 우아한 코드 조각이 엉망인 패치와 특수한 경우로 바뀌는 것을 나타낸다.
Refactoring은 코드를 재구성하는 행위이다. 다음 목록에는 코드를 리팩토링하는 데 사용할 수 있는 기술의 예가 포함되어 있다. 더 포괄적인 목록을 얻으려면 Appendix B의 리팩토링 도서 중 하나를 참조한다.
- 더 많은 추상화를 허용하는 기술:
- Encapsulate field (필드 캡슐화): 필드를 비공개로 만들고 getter와 setter 메서드를 사용하여 액세스 권한을 부여한다.
- Generalize type (유형 일반화): 더 많은 코드 공유를 허용하려면 더 일반적인 유형을 만든다.
- 더 논리적인 조각으로 코드를 나누는 기술:
- Extract method (추출 메서드): 큰 메서드의 일부를 더 쉽게 이해할 수 있도록 새로운 메서드로 변경한다.
- Extract class (추출 클래스): 코드의 일부를 기존 클래스에서 새 클래스로 이동한다.
- 이름과 코드의 위치를 개선하는 기술:
- Move method or move fiels (이동 메서드나 이동 필드): 더 적절한 클래스나 소스 파일로 이동한다.
- Rename method or rename field (이름 변경 메서드나 이름 변경 필드): 목적을 더 잘 나타내기 위해 이름을 변경한다.
- Pull up (상향): 객체 지향 프로그래밍에서 기본 클래스로 이동한다.
- Push down (하향): 객체 지향 프로그래밍에서 파생 클래스로 이동한다.
코드가 읽을 수 없는 조밀한 블록으로 시작하든 그냥 그렇게 진화하든 간에 누적된 해킹 코드를 주기적으로 제거하려면 리팩토링이 필요하다. 리팩토링을 통해, 기존 코드를 다시 검토하여 더 읽기 쉽고 유지 관리할 수 있도록 다시 작성한다. 리팩토링은 코드 분해를 다시 검토할 수 기회이다. 코드의 목적이 변경되었거나 처음부터 분해되지 않은 경우, 코드를 리팩토링할 때 코드를 검토하여 더 작은 부분으로 분해해야 하는지 여부를 결정한다.
코드를 리팩토링할 때, 발생할 수 있는 모든 결함을 포착하는 테스트 프레임워크에 의존할 수 있는 것이 중요하다. Chapter 30에서 논의되는 단위 테스트는 특히 리팩토링 중에 실수를 찾는 데 매우 적합하다.
Decomposition by Design (설계에 의한 분해)
모듈식 분해를 사용하고 나중으로 미룰 수 있는 부분을 고려하여 모든 모듈, 메서드나 함수에 접근하는 코드를 작성할 때, 모든 기능을 전체적으로 구현하는 경우보다 일반적으로 프로그램의 밀도가 낮고 조직화된다.
물론 코딩을 시작하기 전에 프로그램을 설계해야 한다.
Decomposition in This Book (이 책에서 분해)
이 책의 많은 예제에서 분해를 볼 수 있다. 많은 경우에 예제와 관련이 없고 너무 많은 공간을 차지하기 때문에 구현이 표시되지 않은 메서드가 참조될 수 있다.
NAMING (이름 지정)
C++ 컴파일러에는 다음과 같은 몇 가지 명명 규칙이 있다:
- 이름은 숫자로 시작할 수 없다(예: 9to5).
- 이중 밑줄이 포함된 이름(예: my__name)은 예약되어 있어 사용되지 않는다.
- 밑줄로 시작하고 그 뒤에 대문자가 오는 이름(예: _Name)은 항상 예약되어 있으므로 사용하지 않아야 한다.
- 밑줄로 시작하는 전역 네임스페이스의 이름(예: _name)은 예약되어 있어 사용되지 않는다.
이러한 규칙 외에도, 이름은 사용자와 동료 프로그래머가 프로그램의 개별 요소를 작업하는 데 도움이 되도록 존재한다. 이러한 목적을 감안할 때, 프로그래머가 얼마나 자주 불특정하거나 부적절한 이름을 사용하는지 놀랍기만 하다.
Choosing a Good Name (좋은 이름 선택)
변수, 메소드, 함수, 파라미터, 클래스, 네임스페이스 등에 대한 최상의 이름은 각 항목의 목적을 정확하게 설명한다. 이름은 유형이나 특정 용도와 같은 추가 정보를 의미 할 수도 있다. 물론 실제 테스트는 다른 프로그래머가 특정 이름으로 전달하려는 내용을 이해하는지 여부이다.
조직에 적용되는 규칙 외에는 이름 지정에 대한 정해진 규칙은 없다. 그러나 드물게 적절하지 않은 이름이 있다. 다음 테이블은 연속으로 명명된 양쪽 끝에 있는 일부 이름을 보여준다:
| GOOD NAMES | BAD NAMES |
| sourceName, destinationName 두 개체가 구별 |
thing1, thing2 너무 일반적 |
| g_settings 글로벌 상태 전달 |
globalUserSpecificSettingsAndPreferences 너무 길다 |
| m_nameCounter 멤버 데이터 상태 전달 |
m_NC 너무 모호하고, 너무 짧다 |
| calculateMarigoldOffset() 간단하고 정확 |
doAction() 너무 일반적이고 정확하지 않음 |
| m_typeString 눈이 편하다 |
typeSTR256 컴퓨터만이 사랑할 수 있는 이름 |
| m_IHateLarry 용납할 수 없는 내부 농담 |
|
| errorMessage 설명적인 이름 |
string 설명할 수 없는 이름 |
| sourceFile, destinationFile 약어 없음 |
srcFile, dstFile 약어 |
Naming Conventions (이름 지정 규칙)
이름을 선택하는 데 항상 많은 생각과 창의성이 필요한 것은 아니다. 대부분의 경우 이름 지정에 표준 기술을 사용하고 싶을 것이다. 다음은 표준 이름을 사용할 수 있는 데이터 유형 중 일부이다.
Counters
프로그램 경력 초기에 변수 i를 카운터로 사용하는 코드를 보았을 것이다. i와 j를 각각 카운터와 내부 루프 카운터로 사용하는 것은 일반적이다. 그러나 중첩 루프에 주의해야 한다. "j 번째" 요소를 실제로 의미할 때 "i 번째" 요소를 참조하는 것은 일반적인 실수이다. 2차원 데이터로 작업할 때, i와 j 대신 raw과 column을 인텍스로 사용하는 것이 더 쉬울 것이다. 일부 프로그래머는 카운터 outerLoopIndex와 innerLoopIndex를 사용하는 것을 선호하고 일부 프로그래머는 i와 j를 루프 카운터로 사용하는 것을 싫어한다.
Prefixes
많은 프로그래머는 변수의 유형이나 사용법에 대한 정보를 제공하는 문자로 변수 이름을 시작한다. 다른 한편으로, 미래에 그 이상 진화하는 코드를 유지 관리하기 어렵게 만들 수 있기 때문에 어떤 종류의 접두사도 사용을 승인하지 않는 프로그래머들도 있다. 예를 들어, 멤버 변수가 static에서 non-static으로 변경된 경우 사용된 모든 해당 이름을 바꿔야 한다. 이름을 바꾸지 않으면, 이름이 의미를 계속 전달하지만 이제는 잘못된 의미이다.
하지만 선택의 여지가 없는 경우가 많으며, 회사의 지침을 따라야 한다. 다음 테이블은 몇 가지 가능한 접두사를 보여준다.
| PREFIX | EXAMPLE NAME | LITERAL PREFIX MEANING | USAGE |
| m m_ |
mData m_data |
"member" | Data member within a class (클래스 내의 데이터 멤버) |
| s ms ms_ |
sLookupTable msLookupTable ms_LookupTable |
"static" | Static variable or data member (정적 변수나 데이터 멤버) |
| k | kMaximumLength | "konstant" (German for "constant") |
A constant value. Some programmers omit any prefix to indicate constants. (상수 값. 일부 프로그래머는 상수를 나타내기 위해 접두사를 생략한다.) |
| b is |
bCompleted isCompleted |
"Boolean" | Designates a Boolean value (부울 값 지정) |
Hungarian Notation
헝가리안 표기법은 Microsoft Windows 프로그래머에게 널리 사용되는 변수와 데이터 멤버의 명명 규칙이다. 기본 아이디어는 m과 같은 단일 문자 접두사를 사용하는 대신, 추가 정보를 나타내기 위해 더 자세한 접두사를 사용해야 한다는 것이다. 다음 코드 라인은 헝가리안 표기법의 사용을 보여준다:
char* pszName; // psz means "pointer to string, zero-terminated"Hungarian notation(헝가리안 표기법)이라는 용어는 발명가인 Charles Simonyi가 헝가리인이라는 사실에서 비롯되었다. 일부에서는 헝가리안 표기법을 사용하는 프로그램이 외국어로 작성된 것처럼 보인다는 사실을 정확히 반영한다고도 한다. 이러한 후자의 이유로 일부 프로그래머는 헝가리안 표기법을 싫어하는 경향이 있다. 이 책에서, 접두사는 사용되지만, 헝가리안 표기법은 사용되지 않는다. 적절하게 명명된 변수는 접두사 외에 추가 컨텍스트 정보가 많이 필요하지 않다. 예를 들어, m_name이라는 데이터 멤버가 모든 것을 말해준다.
참고
좋은 이름은 코드를 읽을 수 없게 만들지 않고 목적에 대한 정보를 전달한다.
Getters and Setters
클래스에 m_status와 같은 데이터 멤버가 포함된 경우, getStatus()라는 getter와 setStatus()라는 setter를 통해 멤버에 대한 액세스를 제공하는 것이 일반적이다. 부울 데이터 멤버에 대한 액세스 권한을 부여하려면 일반적으로 is를 get 대신 접두사로 사용한다(예: isRunning()). C++ 언어에는 이러한 방법에 대해 규정된 이름이 없지만, 조직에서는 이 방법이나 유사한 이름 지정 체계를 채택하기를 원할 것이다.
Capitalization
코드에서 다양한 방법으로 이름을 대문자로 사용한다. 코딩 스타일의 대부분의 요소와 마찬가지로, 그룹에서 표준화된 접근 방식을 채택하고 모든 구성원이 해당 접근 방식을 채택하는 것이 중요하다. 지저분한 코드를 얻는 한 가지 방법은 일부 프로그래머가 공백을 나타내는 밑줄(priority_queue)을 사용하여 모든 소문자로 클래스 이름을 지정하도록 하고, 다른 프로그래머는 각 후속 단어를 대문자(PriorityQueue)로 사용하는 것이다. 변수와 데이터 멤버는 거의 항상 소문자로 시작하고 단어를 구분하기 위해 밑줄(my_queue)나 대문자(myQueue)를 사용한다. 함수와 메소드는 전통적으로 C++에서 대문자로 사용되지만, 당신이 보았듯이 이 책에서는 클래스 이름과 구별하기 위해 소문자 함수와 메소드 스타일을 채택했다. 유사한 스타일의 대문자가 클래스와 데이터 멤버 이름에 대한 단어 경계를 나타내는 데 사용된다.
Namespaced Constants
그래픽 사용자 인터페이스로 프로그램을 작성한다고 상상해 보자. 이 프로그램에는 File, Edit와 Help를 포함한 여러 메뉴가 있다. 각 메뉴의 ID를 나타내기 위해 상수(constamt)를 사용하기로 결정할 수 있다. Help 메뉴 ID를 참조하는 상수에 대한 완벽하게 합당한 이름은 Help이다.
Help라는 이름은 메인 윈도우에 Help 버튼을 추가할 때까지 잘 작동한다. 또한 Help 버튼의 ID를 참조하기 위해 상수가 필요하지만 Help는 이미 사용중이다.
이에 대한 가능한 해결책은 Chapter 1, "A Crash Course in C++ and the Standard Library"에서 설명하는 다양한 네임스페이스에 상수를 넣는 것이다. Menu와 Button이라는 두 개의 네임스페이스를 만든다. 각 네임스페이스에는 Help 상수가 있으며, 이를 Menu::Help와 Button::Help로 사용한다. 더 권장되는 또 다른 솔루션은 Chapter 1에서도 소개된 열거형을 사용하는 것이다.
USING LANGUAGE FEATURES WITH STYLE (스타일과 함께 언어 기능 사용)
C++ 언어를 사용하면 읽을 수 없는 모든 종류의 작업을 수행할 수 있다. 이 엉터리 코드를 살펴보자:
i++ + ++i;이 것은 읽을 수 없지만, 더 중요한 것은 그 동작이 C++ 표준에 의해 정의되지 않는다는 것이다. 문제는 i++가 i 값을 사용하지만 증가시키는 부작용이 있다는 것이다. 표준에서는 이 증가를 언제 수행해야 하는지 언급하지 않고, 부작용(증가)은 시퀀스 포인트 ; 뒤에 보여져야 한다. 그러나 컴파일러는 해당 명령문을 실행하는 동안 언제든지 이를 수행할 수 있다. ++i 부분에 사용할 i 값을 아는 것은 불가능하다. 다른 컴파일러와 플랫폼에서 이 코드를 실행하면 다른 값이 나올 수 있다.
다음과 같은 표현은
a[i] = ++i;할당의 오른쪽에 대한 모든 연산의 평가가 왼쪽을 평가하기 전에 완료되도록 보장하는 C++17 이후로는 잘 정의되어 있다. 따라서 이 경우 먼저 i를 증가시킨 다음, a[i]에서 인덱스로 사용한다. 그럼에도 불구하고 명확성을 위해 그러한 표현을 피하는 것이 좋다.
C++ 언어가 제공하는 모든 기능을 사용하여, 언어 기능을 악마가 아닌 문체로 사용할 수 있는 방법을 고려하는 것이 중요하다.
Use Constants (상수 사용)
잘못된 코드는 종종 "magic number(마법의 숫자)"로 가득 차 있다. 일부 함수 코드는 2.71828 또는 24 또는 3600 등을 사용할 수 있다. 왜? 이 값은 무엇을 의미할까? 수학적 배경을 가진 사람들은 2.71828이 초월 값 e의 근사치를 나타낸다는 것을 분명히 알 수 있지만, 대부분의 사람들은 이것을 모른다. C++ 언어는 2.71828, 24, 3600 등과 같이 변경되지 않는 값에 기호 이름을 부여하는 상수를 제공한다. 여기 몇 가지 예가 있다:
const double ApproximationForE { 2.71828182845904523536 };
const int HoursPerDay { 24 };
const int SecondsPerHour { 3'600 };참고
C++20부터 표준 라이브러리에는 미리 정의된 수학 상수 모음이 포함되어 있으며, 모두 <number> 내에 std::numbers namespace에 정의되어 있다. 예를 들어, std::numbers::e, pi, sqrt2, phi 등을 정의한다.
Use References Instead of Pointers (포인터 대신 레퍼런스 사용)
과거에는 종종 C++ 프로그래머가 C를 먼저 배웠다. C에서 포인터는 유일한 레퍼런스 통과 메커니즘이었고, 수년동안 확실하게 잘 작동하였다. 어떤 경우에는 여전히 포인터가 필요하지만, 많은 상황에서 레퍼런스로 전환할 수 있었다. C를 먼저 배웠다면, 레퍼런스가 실제로 언어에 새로운 기능을 추가하지 않는다고 생각할 것이다. 포인터가 이미 제공할 수 있는 기능에 대해 새로운 구문을 도입 했을 뿐이라고 생각할 수 있다.
포인터 대신에 레퍼런스를 사용하면 몇 가지 이점이 있다. 첫번째, 레퍼런스는 메모리 주소를 직접 다루지 않고 nullptr이 될 수 없기 때문에 포인터보다 안전하다. 두번째, 레퍼런스는 스택 변수와 동일한 구문을 사용하고 *와 & 같은 기호를 사용하지 않기 때문에 포인터보다 더 스타일리시하다. 또한 사용하기 쉽기 때문에 스타일 팔레트에 레퍼런스를 적용하는 데 문제가 없다. 불행하게도 일부 프로그래머는 함수 호출에서 &가 보여지면 호출된 함수가 개체를 변경할 것임을 알고 있고, &가 보여지지 않으면 값으로 전달해야 한다고 생각한다. 레퍼런스를 사용하면 함수 프로토타입을 보지 않는 한, 함수가 객체를 변경할지 여부를 알 수 없다고 말한다. 이것은 잘못된 생각이다. 포인터를 전달한다고 해서 자동으로 개체가 수정되는 것은 아니다. 파라미터로 const T*가 될 수도 있다. 포인터와 레퍼런스를 모두 전달하면 함수 프로토타입이 const T*, T*, const T&나 T&를 사용하는지 여부에 따라 개체가 수정되거나 수정되지 않을 수 있다. 따라서 함수가 객체를 변경할 수 있는지 여부를 알기 위해 어쨌든 프로토타입을 볼 필요가 있다.
레퍼런스의 또 다른 이점은 메모리 소유권을 명확히 한다는 것이다. 메소드를 작성 중이고 다른 프로그래머가 객체에 대한 레퍼런스를 전달하면, 객체를 읽고 수정할 수 있다는 것은 분면하지만 메모리를 해제하는 쉬운 방법은 없다. 포인터가 전달되다면, 이는 명확하지 않다. 메모리를 정리하기 위해 객체를 삭제해야 할까? 아니면 호출자가 그렇게 할 것인가? 최신 C++에서 소유권과 소유권 이전을 처리하는 데 선호되는 방법은 Chapter 7, "Memory Management"에서 논의되는 스마트 포인트를 사용하는 것이다.
Use Custom Exceptions (사용자 정의 예외 사용)
C++에서는 예외를 쉽게 무시할 수 있다. 언어 구문에 대한 어떤 것도 예외를 처리하도록 강요하지 않으며, 특수 값(예: -1, nullptr, ...) 반환이나 오류 플래그 설정과 같은 기존 메커니즘을 사용하여 이론적으로 오류 허용 프로그램을 작성할 수 있다. 시그널 오류에 대한 특수 값을 반환할 때, Chapter 1.에서 소개된 [[nodiscard]] 속성을 사용하여 함수 호출자가 반환된 값으로 무언가를 하도록 강제할 수 있다.
그러나 예외는 오류 처리를 위한 훨씬 더 풍부한 메커니즘을 제공하고, 사용자 정의 예외를 사용하면 이 메커니즘을 필요에 맞게 조정할 수 있다. 예를 들어, 웹 브라우저의 사용자 정의 예외 유형에는 오류가 포함된 웹 페이지, 오류 발생 시 네트워크 상태 및 추가 컨텍스트 정보를 지정하는 필드가 포함될 수 있다.
Chapter 14. "Handling Errors"에는 C++의 예외에 대한 풍부한 정보가 포함되어 있다.
참고
언어 기능은 프로그래머를 돕기 위해 존재한다. 좋은 프로그래밍 스타일에 기여하는 기능을 이해하고 활용한다.
FORMATTING (서식)
코드 서식 논쟁으로 많은 프로그래밍 그룹이 분열되고 우정에 금이갔다. 대학에서 내 친구는 if 문에서 공백을 사용하는 문제로 동료와 열띤 토론을 벌였다. 사람들은 모든 것이 괜찮은지 확인하기 위해 들렸다.
조직에 코드 서식 지정에 대한 표준이 있는 경우, 운이 좋은 것이다. 그들이 가지고 있는 표준이 마음에 들지 않을 수도 있지만, 적어도 그것에 대해 논쟁할 필요는 없다.
코드 서식 지정에 대한 표준이 없는 경우, 조직에 도입하는 것이 좋다. 표준화된 코딩 지침은 팀의 모든 프로그래머가 동일한 명명 규칙, 서식 지정 규칙 등을 따르도록 하여 코드를 보다 균일하고 이해하기 쉽게 만든다.
소스 코드 컨트롤 시스템에 코드를 커밋하기 직전에 특정 규칙에 따라 코드를 서식화할 수 있는 자동화된 도구가 있다. 일부 IDE에는 이러한 도구가 내장되어 있으며, 예를 들어 파일을 저장할 때 코드를 자동으로 서식화할 수 있다.
팀의 모든 인원이 자신만의 방식으로 코드를 작성하는 경우, 가능한 한 관용을 유지한다. 보다시피, 일부 관행은 단지 취향의 문제인 반면, 다른 관행은 실제로 팀으로 작업하기 어렵게 만든다.
The Curly Brace Alignment Debate (중괄호 정렬 논쟁)
아마도 가장 자주 논의되는 사항은 코드 블록을 표시하는 중괄호를 어디에 둘 것인가이다. 중괄호 사용에는 여러 스타일이 있다. 이 책에서 중괄호는 클래스, 함수, 메소드의 경우를 제외하고, 선행 문장과 같은 라인에 둔다. 이 스타일은 다음(과 이 책 전체)의 코드에 나와 있다:
void someFunction()
{
if (condition()) {
cout << "condition was true" << endl;
} else {
cout << "condition was false" << endl;
}
}이 스타일은 들여쓰기로 코드 블록을 계속 표시하면서 수직 공간을 절약한다. 일부 프로그래머는 수직 공간의 보존이 실제 코딩과 관련이 없다고 주장한다. 더 자세한 스타일은 다음과 같다:
void someFunction()
{
if (condition())
{
cout << "condition was true" << endl;
}
else
{
cout << "condition was false" << endl;
}
}일부 프로그래머는 수평 공간을 자유롭게 사용하여 다음과 같은 코드를 생성한다:
void someFunction()
{
if (condition())
{
cout << "condition was true" << endl;
}
else
{
cout << "condition was false" << endl;
}
}또 다른 논쟁의 요점은 단일 문장 주위에 중괄호를 둘 것인지 여부이다. 예를 들면 다음과 같다:
void someFunction()
{
if (condition())
cout << "condition was true" << endl;
else
cout << "condition was false" << endl;
}분명하게, 나는 증오 메일을 원하지 않기 때문에 특정 스타일을 권장하지 않는다. 개인적으로 중괄호는 잘못 작성된 특정 C 스타일 매크로(Chapter 11. "Odds and Ends" 참조)로부터 보호하기 위해 사용하거나, 향후 명령문의 안전한 추가를 위해 단일 명령문에 대해서도 항상 중괄호를 사용한다.
참고
코드 블록을 나타내는 스타일을 선택할 때 중요한 고려 사항은 단순히 코드를 보고 어떤 블록이 어떤 조건에 속하는지 얼마나 잘 파악 할수 있는가이다.
Coming to Blows over Spaces and Parentheses (공백과 괄호에 대해 전하기)
개별 코드 라인의 서식 지정도 불일치의 원인이 될 수 있다. 다시 말하지만, 특정 접근 방식을 옹호하지는 않겠지만 여기에 표시된 몇 가지 스타일을 접하게 될 것이다.
이 책에서는 다음과 같이 키워드 뒤에 공백, 연산자의 앞과 뒤에 공백, 파라미터 목록이나 호출의 모든 쉼표 뒤에 공백, 그리고 괄호를 사용하여 작업 순서를 명확히 한다:
if (i == 2) {
j = i + (k / m);
}다음에 표시된 대안은 키워드와 왼쪽 괄호 사이에 공백이 없는 함수와 같은 스타일을 처리한다. 또한 if 문 내에서 연산 순서를 명확히 하기 위해 사용하는 괄호는 의미상 관련이 없기 때문에 생략되었다.
if( i == 2 ) {
j = i + k / m;
}그 차이는 미묘하고 어느 것이 더 나은지에 대한 판단은 독자에게 맡기지만, if가 함수가 아니라는 점을 지적하지 않고는 문제에서 이동할 수가 없다.
Spaces, Tabs, and Line Breaks (공백, 탭과 라인 바꿈)
공백과 탭의 사용은 단순히 스타일을 선호하는 것이 아니다. 그룹이 공백과 탭에 대한 규칙에 동의하지 않으면, 프로그래머들이 공동으로 작업할 때 큰 문제가 발생하게 된다. 가장 명백한 문제는 Alice가 4칸 탭을 사용하여 코드를 들여쓰고, Bob이 5칸 탭을 사용할 때 발생한다. 동일한 파일에서 작업하는 경우, 둘 다 코드를 제대로 표시할 수 없다. Alice가 동일한 코드를 편집하는 것과 동시에 Bob이 탭을 사용하도록 코드를 다시 서식화할 때 더 심각한 문제가 발생한다. 많은 소스 코드 컨트롤 시스템은 Alice의 변경 사항을 병합할 수 없다.
전부는 아니지만, 대부분의 편집기에는 공백과 탭에 대한 구성 가능한 설정이 있다. 일부 환경은 코드를 읽을 때 코드의 서식에 적응하거나, 작성에 Tab 키를 사용하더라도 항상 공백을 사용하여 저장한다. 유연한 환경이 있으면, 다른 사람의 코드로 작업할 가능성이 더 높아진다. 탭은 길이에 제한이 없고 공백은 항상 공백이기 때문에 탭과 공백이 다르다는 점을 기억해야 한다.
마지막으로, 모든 플랫폼이 동일한 방식으로 라인 바꿈을 나타내는 것은 아니다. 예를 들어 Windows는 라인 바꿈에 \r\n을 사용하는 반면, Linux 기반 플랫폼은 일반적으로 \n을 사용한다. 회사에서 여러 플랫폼을 사용하는 경우 사용할 라인 바꿈 스타일에 동의해야 한다. 여기에서도 필요한 라인 바꿈 스타일을 사용하도록 IDE를 구성하거나, 소스 코드 컨트롤 시스템에 코드를 커밋할 때와 같은 예에서 자동화 도구를 사용하여 라인 바꿈을 자동으로 수정할 수 있다.
STYLISTIC CHALLENGES (스타일 도전)
많은 프로그래머들이 이번에는 모든 것을 제대로 할 것이라고 다짐하면서 새로운 프로젝트를 시작한다. 변수나 파라미터를 변경하지 않아야 할 때마다 const로 표시할 것이다. 모든 변수는 명확하고 간결하며 읽을 수 있는 이름을 갖는다. 모든 개발자들은 이어지는 라인에 왼쪽 중괄호를 넣고 탭과 공백에 대한 표준 텍스트 편집기와 규칙을 채택한다.
여러 가지 이유로 이러한 수준의 스타일 일관성을 유지하기가 어렵다. const의 경우 프로그래머가 사용 방법에 대해 교육을 받지 못하는 경우가 있다. 결국에는 const -savvy가 아닌 오래된 코드나 라이브러리 함수를 보게 될 것이다. 예를 들어, const 파라미터를 허용하는 함수를 작성 중이고 non-const 파라미터를 허용하는 레거시 함수를 호출해야 한다고 가정해보자. 레거시 코드를 수정하여 const를 인식할 수 없는 경우(third-party library이기 때문에), 레거시 함수가 non-const 인수를 수정하지 않을 것이라고 절대적으로 확신하는 경우 좋은 프로그래머는 파라미터의 const 속성을 일시적으로 중단하는 const_cast()(Chapter 1. 참조)를 사용할 것이다. 하지만 경험이 없는 프로그래머는 호출하는 함수에서 const 속성을 풀기 시작하여 다시 한 번 const를 절대 사용하지 않는 프로그램으로 끝난다.
때로는 스타일의 표준화가 프로그래머의 개인적인 취향과 편견에 반하는 경우도 있다. 팀 문화로 인해 엄격한 스타일 지침을 적용하는 것이 비실용적일 수 있다. 이러한 상황에서는 어떤 요소를 표준화(예: 변수 이름과 탭)해야 하고 개인(아마도 공백과 주석 스타일)에게 맡기는 것이 안전한지를 결정해야 할 수 있다. 스타일 "bugs(버그)"를 자동으로 수정하거나 코드 오류와 함께 스타일 문제에 플래그를 지정하는 스크립트를 얻거나 작성할 수도 있다. Microsoft Visual C++와 같은 일부 개발 환경은 지정한 규칙에 따라 코드의 자동 서식을 지원한다. 따라서 항상 구성된 지침을 따르는 코드를 작성하는 것이 간단하다.
SUMMARY (요약)
C++ 언어는 사용 방법에 대한 공식적인 지침 없이 다양한 스타일 도구를 제공한다. 궁극적으로 모든 스타일 규칙은 그것이 얼마나 널리 채택되고 코드 가독성에 얼마나 도움이 되는지에 따라 결정된다. 팀의 일원으로 코딩할 때 사용할 언어와 도구에 대한 논의의 일부로 프로세스 초기에 스타일 문제를 제기해야 한다.
스타일에 대한 가장 중요한 점은 그것이 프로그래밍의 중요한 측면이라는 것을 인식하는 것이다. 다른 사람이 사용할 수 있도록 하기 전에 코드의 스타일을 확인하는 방법을 배워야 한다. 상호 작용하는 코드에서 좋은 스타일을 인식하고 당신과 당신의 조직이 유용하다고 생각하는 규칙을 채택한다.
이 장으로 이 책의 첫 부분을 마무리한다. 다음 장에서는 높은 수준의 소프트웨어 설계에 대해 설명한다.
EXERCISES (연습 문제)
다음 연습 문제를 풀면서, 이 장에서 설명하는 내용를 연습할 수 있다. 모든 연습 문제에 대한 솔루션은 책 웹 사이트(www.wiley.com/go/proc++5e)에서 코드를 다운로드하여 사용할 수 있다. 그러나 연습 문제를 풀다가 막힌 경우, 웹 사이트에서 솔루션을 보기 전에 먼저 이 장의 일부를 다시 읽고 스스로 답을 찾기 바란다.
코드 주석과 코딩 스타일은 주관적이다. 다음 연습 문제에는 하나의 완벽한 답이 없다. 웹 사이트의 솔루션은 연습 문제에 대한 가능한 많은 정답 중 하나를 제공한다.
Exercise 3-1: Chapter 1에서 직원 기록 시스템의 예를 설명했다. 그 시스템에는 데이터베이스가 있으며, 데이터베이스의 메소드 중 하나는 displayCurrent()이다. 다음은 몇 가지 주석이 있는 해당 메서드의 구현이다:
void Database::displayCurrent() const // The displayCurrent() method
{
for (const auto& employee : m_employees) { // For each employee...
if (employee.isHired()) { // If the employee is hired
employee.display(); // Then display that employee
}
}
}이 주석들에 문제가 있다고 보나요? 왜 그렇게 생각하나요? 더 나은 의견을 제시할 수 있나요?
Exercise 3-2: Chapter 1의 직원 기록 시스템에는 데이터베이스 클래스 있다. 다음은 세 가지 메서드만 있는 해당 클래스의 코드 조각이다. 이 코드 조각에 적절한 JavaDoc 스타일 주석을 추가한다. 이러한 방법이 정확히 무엇을 하는지에 대해서는 Chapter 1을 참조한다.
class Database
{
public:
Employee& addEmployee(const std::string& firstName,
const std::string& lastName);
Employee& getEmployee(int employeeNumber);
Employee& getEmployee(const std::string& firstName,
const std::string& lastName);
// Remainder omitted...
};
Exercise 3-3: 다음 클래스에는 여러 가지 이름 지정 문제가 있다. 당신은 모든 문제를 발견하고 더 나은 이름을 제안할 수 있나요?
class xrayController
{
public:
// Gets the active X-ray current in μA.
double getCurrent() const;
// Sets the current of the X-rays to the given current in μA.
void setIt(double Val);
// Sets the current to 0 μA.
void 0Current();
// Gets the X-ray source type.
const std::string& getSourceType() const;
// Sets the X-ray source type.
void setSourceType(std::string_view _Type);
private:
double d; // The X-ray current in μA.
std::string m_src__type; // The type of the X-ray source.
};
Exercise 3-4: 다음 코드 조각이 주어지면, 조각을 세 번 다시 서식화한다. 먼저 중괄호를 자체 라인에 넣은 다음, 중괄호 자체를 들여쓰고 마지막으로 단일 문장 코드 블록의 중괄호를 제거한다. 이 연습 문제를 통해 다양한 서식 스타일과 코드 가독성에 미치는 영향을 파악할 수 있다.
Employee& Database::getEmployee(int employeeNumber)
{
for (auto& employee : m_employees) {
if (employee.getEmployeeNumber() == employeeNumber) {
return employee;
}
}
throw logic_error { "No employee found." };
}
Notes (참고)
1 Preconditions(전제 조건)은 클라이언트 코드가 함수를 호출하기 전에 충족해야 하는 조건이다. Postconditions(사후 조건)은 함수가 실행을 완료했을 때 충족되어야 하는 조건이다.
'Programming Language > Professional C++' 카테고리의 다른 글
| Professional C++ - 7. Memory Management (0) | 2022.12.19 |
|---|---|
| Professional C++ - 6. Designing for Reuse (0) | 2022.11.03 |
| Professional C++ - 5. Designing with Objects (0) | 2022.10.10 |
| Professional C++ (0) | 2022.09.08 |
| Professional C++ - 4. Designing Professional C++ Programs (0) | 2022.09.08 |